-
hashing
- dictionary (key, value)를 implementing
- insert, search, delete 연산의 average-case : O(1)
- find minimum과 같은 sort연산은 비효율적이다.
dictionary
- dynamic-set data structure. 동적으로 크기가 변한다.
- operation : insert, search, delete
hash table
- key : hash function의 input.
- U : universe of keys. 모든 가능한 키의 집합
- K : actual keys. 딕셔너리에 매칭된 실제 키
- Hash Table을 만들 때 U를 저장할 필요 없다. |k|=n의 사이즈를 테이블로 만든다.
- 하지만 좁은 장소에 여러개를 저장해야하므로 hash 충돌이 생겨 direct-addressing(인덱스로 직접 접근)을 잃을 수 있다.

hash table - hash function h: key를 hash로 변환. 서로 다른 key가 같은 hash 가 되는것을 hash collision이라고 한다.
- hash : hash function의 output. h[k]
- value : slot에 저장되는 값. key와 매칭되어있다.
- slot : 저장소
- ex)

- h(i) = i%10 (=i mod 10) 에 add 41을 한다면
- hash function : h(i)=i%10
- h(41) = 41%10 = 1
- key : 41, hash : 1,
- slot : 0,1,2, ...9의 저장소중 hash값과 동일한 1에 value 41을 저장한다.
좋은 해시함수는?
- 계산하기 간단해야한다.
- 최대한 랜덤한 함수여야 한다. 즉, 고르게 분포되어야 한다. (simple uniform function) 연관이 있는 key라 하더라도 같은 slot에 들어가는 경우를 최소화해야한다. -> 충돌(collision)의 확률 줄여줌
- 해시값들은 서로 연관이 없으며 독립적으로 생성된다. -> collision의 반복을 줄여줌
- 가장 대표적인 방법으로 division method와 multiplication method가 있다.
Simple uniform hash
- 해시값들이 나올 확률이 동일해야한다.
- 하지만 실제 상황에서 이를 만족하는 함수는 매우 찾기 힘들다. -> 그래서 충돌을 줄이는 방법으로
Division Method
moduler(나머지) 연산을 이용. m으로 나눈다 -> h(k) = k mod m 로 표현
m은 테이블의 크기를 나타내게 된다.
장점 : 빠르며 한가지 연산만을 요구한다.
단점 : m을 2의 지수승을 고르거나, 소수가 아닌 수를 고르면 충돌이 반복적으로 생긴다.
즉 m을 고를 때 2(or 10)의 지수승에 가깝지 않으며 소수인 수를 고른다.
The Multiplication Method
h(x)=(xA mod 1)*m (0<A<1인 상수)
m은 굳이 소수일 필요 없다. 보통 2의 지수승으로 잡는다.
장점 : m값이 중요하지 않다. 즉, m은 굳이 소수일 필요 없다. 보통 2의 지수승으로 잡는다.
Universal hashing
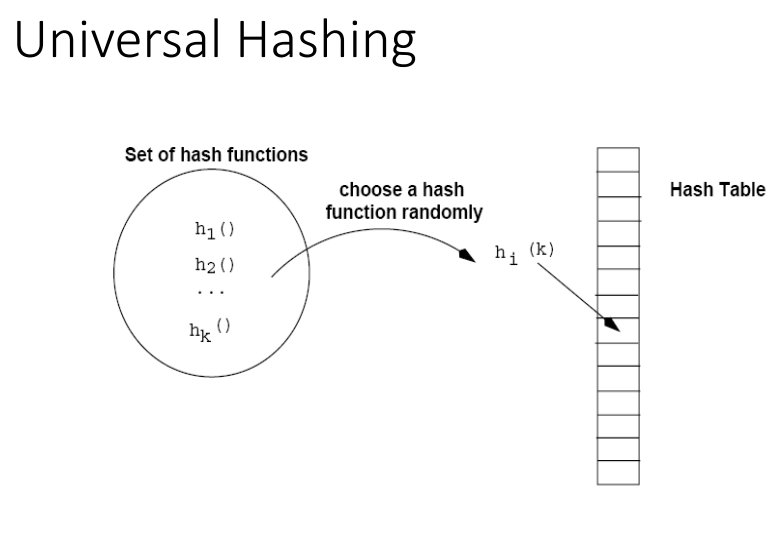
- malicious adversary(공격자)가 모든 key값이 같은 slot으로 가게 만드는것을 방지
- 같은 자리에 여러 개의 키가 해시되는것을 막기위해서 사용한다.
- 매번 다른 랜덤 해시함수를 사용한다.
- 랜덤 해시함수는 실제 저장되는 키와는 관련이 없게 된다.
- 랜덤함수는 좋은 해시함수를 쓴다.
- Universal hash function의 정의
H : 전체집합 U를 {0,1,2,...,m-1} 로 대응시키는 hash function들의 유일한 집합.
x와 y가 다를 때, |h(x)=h(y)|=|H|/m 이다. 즉 두 키의 충돌이 일어날 확률을 1/m. 즉 골고루 분포됨
- 장점
- 저장되는 키값과 관계없이 평균적으로 좋은 결과를 얻는다.
- 어떤 input이 오더라도 최악의 경우로 가지 않는다.
- 연산이 오래걸리는 hash function이 있을 때 이것이 걸릴 확률은 매우 적다.
Load Factor(적재율)
해시 테이블 크기 대비 키의 갯수. 즉 a = N/M (a: 적재율, N : number of key, M:number of slots)
Collision(충돌)
- Hash table의 한 slot에 여러개의 key들이 들어가는것.
- collision은 피할 수 없다. 따라서 충돌을 최소화 한다.
- collision을 피하는 방법
- Chaining
- Open addressing (Linear probing, Quadratic probing, double hashing)
Chaining

- 데이터들을 포인터를 이용해 체인형태로 엮어나간다. 충돌이 생기면 linked list로 이어나간다.
- 추가적인 linked list 필요
- insert : O(1)
- delete : doubly-linked list 일 때O(1), singled-linked list일 때 길이에 비례
- search : 연결리스트이 길이만큼, average case : O(1+a) (a: 적재율), 최악의 경우 O(n)+hash function의 연산 시간
Open addressing
- slot이 차있으면 다른 빈공간을 찾는 방식이다.
- Collision이 일어나도 모든 데이터를 테이블에 저장하므로 추가적인 공간이 필요하지 않다. (m>n일 때 사용)
- 데이터를 모두 직접 읽기때문에 linked list사용을 하지않아도 된다. 즉, 포인터를 사용하지 않는다.
- open addressing은 delete 연산이 어렵다. 충돌이 일어난 것들의 길이 있기 때문에 slot을 비워둘 수가 없다. 따ㅏㄹ서 지우려면 지워진 데이터에 마킹을 해줘야한다.
- search time은 probe sequence에 달려있다. 즉, 어떤 식으로 빈공간을 찾는지에 달려있다.
- Linear probing, Quadratic probing, double hashing 이 있다.
- average O(1)
Linear probing
- Collision이 발생하면 바로 다음 index에 데이터를 저장한다. Collision이 일어나지 않을 때 까지 반복한다.
- h(k,i) = h(h(k)+i) mod m, i=0,1,2,...
- 문제점 : primary clustering problem 이 생긴다. 이게 생기면 slot들의 long chunks가 생겨서 몇몇의 slot은 일어날 확률이 더 높아진다. 이때문에 average insert와 search time이 증가한다.
Quadratic probing
- Linear probing의 clustering 을 해결하기위해 Collision이 발생하면 2차식으로 점프하며 slot에 데이터를 넣는다.
- h(k,i)=(h'(k)+c1*i+c2*i^2) mode m, i=0,1,2,...
- 문제점 : secondary clustering이 생긴다. 초기 해시값이 같으면 그 이후의 해시값도 다 같아져서 연속 충돌이 일어난다.
Double hashing
- 해시함수를 2개 사용한다.
- h(k,i) = (h1(k)+i*h2(k)) mod m, i=0,1,2,...
- 장점 : clustering 문제를 피할 수 있다.
- 문제점 : 원소를 delete하는것이 힘들다.
Performance goal for dictionary operations
- average O(log n) -> BST
- worst-case O(log n) -> balanced BST (AVL tree)
- dictionary operation average O(1) -> hashing (but worst-case is O(n))
'알고리즘' 카테고리의 다른 글
Greedy Algorithm(그리디 알고리즘) (0) 2020.12.13 Dynamic Programming (동적 계획법) (0) 2020.12.13 B-Tree (0) 2020.12.11 AVL Tree (0) 2020.12.11 Binary Search Tree (이진 탐색 트리) (0) 2020.12.11