-
[NLP]언어 모델 LM(Language Model)자연어처리NLP 2021. 4. 9. 11:24
LM(Language Model)
- 언어라는 현상을 모델링 하고자 단어 시퀀스에 확률을 할당하는 모델
- 단어들로 모르는 단어를 예측
- 문장이 적절한지 판단
- 통계를 이용한 방법(SLM, 전통적 접근 방식)과 인공신경망(GPT, BERT...)을 이용한 방법이 있다.
- 목적 : 기계 번역, 오타 교정, 음성 인식 등 에서 언어 모델을 활용하여 보다 적합한 문장을 찾아낼 수 있다.
CLM(Conditional Language Modeling)
다음 단어의 등장 확률
(W: 단어 시퀀스, w: 단어 하나, n개의 단어 등장)
단어 시퀀스의 확률
P(W) = P(w1, w2, w3, ...wn)
다음 단어 등장 확률
P(wn | w1,w2,...,n-1)
전체 단어 시퀀스 W의 확률
전체 단어 시퀀스 W의 확률은 모든 단어가 예측된 후 알 수 있다.

문장의 확률은 이전 단어들의 사후 확률으로부터 계산할 수 있다.
문장이 길어지면 곱셈이 많아지며 확률이 매우 낮아져 정확한 계산이나 표현이 어려워지고 연산속도도 느려짐 → 로그를 취해 덧셈으로 바꾼다.
한국어는 교착어(접사, 조사에 따라 의미/역할이 달라짐)이기 때문에 희소성이 증가. (ex. 과학+자, 과학+실)
단어의 어순이 중요하지 않은 경우 단어간의 학률 계산에 불리함 (ex. 나는 밥을 먹었다. 나는 먹었다. 밥을. ) → 확률이 퍼지는 현상이 나타남.
N-gram
전체 단어 조합이 아닌 일부 단어 조합의 출현 빈도만 계산하여 확률 추정(희소성 해결)
전체 단어 조합의 경우, 아예 출현 빈도를 구할 수 없거나 확률이 너무 낮아짐
N-gram and markov 가정
마르코프 가정 : 특정 시점의 상태확률은 그 직전 상태에만 의존한다.
대부분 3-gram 을 사용
문장 전체의 확률에 대해 마르코프 가정을 통해 해당 문장의 확률을 근사할 수 있게됨. (훈련 코퍼스에서 보지 못한 문장도 확률 추정 가능)
언어 모델의 일반화
일반화 : 좋은 머신러닝은 훈련 데이터에서 보지 못한 샘플의 예측 능력(일반화 능력) 에 의해 좌우됨
- 스무딩과 디스카운팅
- 문제 : 출현 빈도를 확률값으로 추정할 경우, 훈련 코퍼스에 출현하지 않는 단어 시퀀스에 대한 대처 능력이 떨어짐
- 해결책 : 출현하지 않았다고 확률을 0으로 추정하는 것이 아니라 빈도 값이나 확률 값을 다듬어 줘야 함 → 스무딩, 디스카운팅 : 들쭉날쭉한 출현 횟수 값을 부드럽게 해주는 것
- 방법 : 모든 단어 시퀀스 출현빈도에 상수를 더해준다.
- Kneser-Ney discounting
- 다양한 단어 뒤에 나타나는 단어일수록 훈련 코퍼스에서 보지 못한 단어가 시퀀스로 나타날 가능성이 높다.
- ex) deep learning book의 경우, learning과 book이라는 단어 중에서 machine, deep, supervised, generative... : learning book이 훈련 코퍼스에서 보지 못한 단어 시퀀스에서 나타날 확률이 더 높다고 가정하고 점수를 더 주는 것)
- slim, favorite, fancy, expensive, chaep... : book
- interpolation
- 두 개의 다른 언어모델을 선형적으로 일정 비율 섞어주는 것
- 특정 영역에 특화된 언어 모델 구축시 유용하다.
- 일반 영역의 코퍼스를 통해 구축한 언어 모델을 특정 영역의 작은 코퍼스로 만든 언어모델과 섞어서 특정 영역에 특화된 언어모델을 강화할 수 있다.
- 상호보완적
- back off
- count가 0이 나오면 측정하는 n을 하나씩 줄여서 다시 count한다.
- n-gram 의 확률을 n보다 더 작은 시퀀스에 대해 확률을 구해 interpolation 한다.
- n 보다 더 작은 시퀀스를 활용해 더 높은 smoothing, 일반화 효과 가능
언어 모델의 평가방법
좋은 언어모델이란?
실제 우리가 쓰는 언어와 최대한 비슷하게 확률분포를 근사하는 모델(많이 쓰는 문장 확률 ↑, 적게 쓰는 문장 확률 ↓)
PPL(perplexity)

- 문장의 길이를 반영하여 확률값을 정규화
- 확률값이 높을수록 PPL은 작아짐. PPL은 수치가 낮을수록 좋다.
- 식의 의미 : 뻗어나갈 수 있는 경우의 수 (PPL : 30 → 평균 30개의 후보 단어중에 다음 단어를 선택할 수 있다. )
- PPL = exp(Cross Entropy)
- cross-entropy : 정보량의 평균을 의미. 정보량이 낮으면 확률분포는 sharp, 높으면 flat해짐, 놀람의 정도를 나타내는 수치
참고 : https://hellchujang.tistory.com/16?category=848095
RNNLM(Recurrent Neural Network Language Model)
n-gram 언어모델은 고정된 개수의 단어만을 입력받을 수 있었다. → 시점 (time step)을 도입 → 입력의 길이를 고정하지 않아도 되는 RNNLM
예문 : "What will the fat cat sit on"
테스트 과정(실제 사용할 때)

현재시점의 입력 : 이전시점의 출력
ex) input : what → output : will ...
cat은 what, will, the, fat이라는 시퀀스로 인해 결정된 단어
훈련과정 : 교사 강요(teacher forcing)
- 테스트 과정에서 t 시점의 출력이 t+1 시점의 입력으로 사용되는 RNN 모델을 훈련시킬 때 사용하는 훈련기법
- 훈련할 때 교사 강요를 사용할 경우, 모델이 t 시점에서 예측한 값을 t+1시점에 입력으로 사용하지 않고 t 시점의 레이블, 즉 실제 알고있는 정답을 t+1시점의 입력으로 사용
- 훈련과정에서도 이전시점의 출력을 다음시점의 입력으로 사용하면서 훈련하게되면 한 번 잘못 예측하면 뒤의 예측까지 영향을 미쳐 훈련시간이 느려진다. 따라서 교사강요를 사용하여 빠르고 효과적이게 훈련시킨다.
- what will the fat cat sit on → 이 시퀀스를 모델의 입력으로 넣으면 will the fat cat sit on 을 예측하도록 훈련된다.
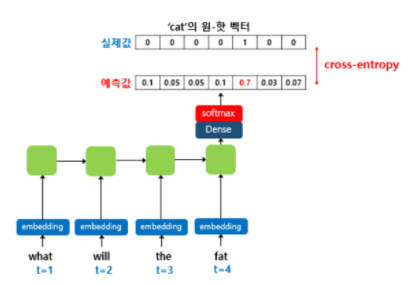
활성화 함수(출력층에서 사용) : softmax 함수
손실함수(모델이 예측한 값과 실제 레이블과의 오차 계산) : cross entropy함수
RNNLM 의 구조

input layer : RNNLM의 time step 은 4로 가정 → 4번째 입력 단어인 fat의 one-hot 벡터가 입력이 된다.
embedding layer : 현 시점의 입력 단어의 one-hot 벡터 xt를 입력받은 RNNML이 임베딩층을 지난다. → 이 임베딩 행렬은 역전파 과정에서 다른 가중치들과 함께 학습된다. one-hot 벡터가 7차원이고 임베딩벡터 M의 크기가 5라면 임베딩 행렬을 7X5 행렬이 된다.
임베딩층은 입력 정수에 대해 dense vector로 매핑하고 이 dense vector은 인공 신경망의 학습 과정에서 가중치가 학습되는것과 같은 방식으로 훈련된다. 이 dense vector을 임베딩 벡터라고 부른다.
lockup table : 주어진 연산에 대해 미리 계산된 결과들의 배열

hidden layer :

output layer : cat의 one-hot 벡터는 출력층에서 모델이 예측한 값의 오차를 구하기 위해 사용될 예정. 이 오차로부터 손실함수를 사용해 인공 신경망이 학습을 하게된다.
V차원(단어 집합 크기) 의 벡터는 소프트맥스(활성화 함수)를 지나면서 각 원소는 0과 1 사이의 실수값을 가지며 총 합은 1이 되는 상태로 바뀐다. 이렇게 나온 벡터를
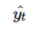
라고 하면 아래와 같다.

- softmax : 입력받은 값을 출력으로 0-1 사이의 값으로 모두 정규화하며 출력값들의 총합은 항상 1이 된다. 분자에 있는 지수함수가 각각 값의 편차를 확대시킨다. 큰값은 더크게, 작은값은 더작게


의 j번째 인덱스가 가진 값은 j번째 단어가 다음단어일 확률을 나타낸다. 이는 실제 정답에 해당되는 단어의 one-hot vector에 가까워져야 한다. 실제 값에 해당되는 다음 단어를 y라고 했을 때, 이 두 벡터가 가까워지게 하기 위해서 손실함수로 cross-entropy 함수를 사용한다. 그리고 역전파가 이루어지며 가중치 행렬들이 학습된다. 이 과정에서 임베딩 벡터값들도 학습된다.
참고 : https://wikidocs.net/46496
'자연어처리NLP' 카테고리의 다른 글
NER(Named Entity Recognition) 개체명 인식 (0) 2021.04.13 [NLP]히든 마코프 모델 HMM(Hidden Markov Model) (0) 2021.04.09 [NLP]Seq2Seq(sequence to sequence)시퀀스 투 시퀀스 (0) 2021.04.09 [NLP]트랜스포머(Transfomer):Attention Is All You Need (0) 2021.04.09