-
[NLP]히든 마코프 모델 HMM(Hidden Markov Model)자연어처리NLP 2021. 4. 9. 12:54
Markov Property
→ A → B → C →
연쇄해서 사건이 일어나므로 특정 상태의 발생 확률은 그 전 상태의 확률값으로 구할 수 있다.
단어 등장확률 계산하면
P(나는 오늘 커피를 마셨다)
= P(나는) X p(오늘 | 나는 ) X P(커피를 | 나는, 오늘 ) X P(마셨다 | 나는, 오늘, 커피를)
뒤로 갈 수록 확률을 계산하기 어려워짐
→ 마르코프 특성 적용
P(나는 오늘 커피를 마셨다)
= P(나는) X p(오늘 | 나는 ) X P(커피를 | 오늘) X P(마셨다 | 커피를) → P(현재|이전) : bigram
but, 특정 상태의 확률값을 구하기 쉽지 않음
이전의 모든 확률을 구하는것은 불가능.
→ 미래의 상태는 오직 현재 상태의 영향만 받는다 라고 가정
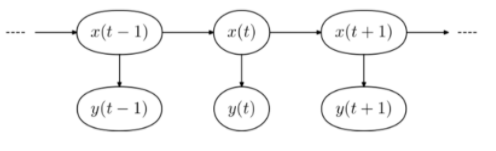
Markov Chain
Markov property 를 지닌 이산확률과정
순차 데이터를 확률적으로 모델링하는 생성모델(Generative Model)
한 상태에서 다른 상태로의 전이(transition)은 그동안 상태전이에 대한 긴 history를 필요로하지 않고 바로 직전 상태에서의 전이로 추청할 수 있다.
sequence
월 : 코카 → 화 : 펩시 → 수 : 펩시 → ...

상태 전이 확률 행렬 (state transition probability matrix) (A)

state : {코카, 펩시}
모레의 확률변화는 오늘과 내일의 전이가 연속되어 일어나는 경우이기 때문에 아래와같이 전이행렬을 곱하여 계산

1일 후 펩시의 경우

이가 반복된다면 어느순간 전이행렬이 변하지 않는 상태가 온다. 이를 안정상태라고 한다.
Hidden Markov Model

각 상태가 마르코프 체인을 따르되 시스템이 보이지 않는 은닉된 상태와 관찰 가능한결과 두가지로 이루어져있다고 보는 모델
Observable sequence는 순차적 특성을 반영하는 Hidden sequence에 종속
예) 지하에 갇혀있는데 날씨에 대한 확률을 구해야 할 경우 → 비와 유의미한 정보를 갖는 데이터를 이용한다. 사람들이 착용한 것들 등으로 파악한다. 이 때, 비 : Hidden 영역, 사람들이 착용한 것들 : Observation

특정 state의 해당 관찰값이 보일 확률을 emission probability(방출 확률) 이라고 한다.
parameter of HMM : λ = {A, B, π}
A(aij) : State transition probability matrix(상태 전이 확률 행렬)
- HMM이 작동하는 도중 다음 상태를 결정
- 각 원소의 총 합은 1
B(bij) : Emission probability matrix(방출 확률 행렬) : B = |bj(vk)|
- HMM이 어느 상태에 도달했을 때 그 상태에서 관측될 확률 결정
- bj(vk) : 은닉상태 bj에서 관측지 vk가 도출될 확률
- bj(vk) = P(ot=vk | qt=sj)
π = Initial probability distribution (state 초기확률)
- HMM을 가동시킬 때 어느 상태에서 시작할지 결정
- πi → si 에서 시작할 확률
- π 총합은 1
https://bioinformaticsandme.tistory.com/53
https://ratsgo.github.io/machine%20learning/2017/03/18/HMMs/
Likelihood
모델 λ가 주어졌을 때 관측치 O가 나타날 확률을 가리킨다. → P(O|λ)
즉 모델λ이 관측치 하나를 뽑았는데 그 관측치가 O일 확률.
베이즈정리
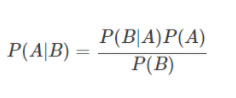
P(B) : 정규화 상수, evidence, 확률의 크기 조정 → 기침을 할 확률
P(A|B) : 사후확률 → 기침을 하는 사람이 감기일 확률 → 조사하기 어려움
P(A) : 사전확률 → 감기에 걸릴 확률
P(B|A) : likelihood → 감기에 걸린 사람이 기침을 할 확률 → 조사하기 쉬움
베이즈정리는 사전확률로부터 사후확률을 알 수 있게 해준다.
이 경우 관측치는 기침, 모델은 감기.
ex) 분류(classification)문제
B를 입력 데이터 A를 클래스의 집합이다. 즉 B가 입력으로 주어졌을때 어떤 클래스 A_i ( i = 1,2,3,4, ... , n )에 속할 확률 P(A_i | B), 즉 posterior를 계산하는 확률문제이다.
그렇다면 클래스 A_i 들 가운데 가장 높은 확률값을 가지는 클래스를 찾으면 됨
다시 말하면 P(A_1|B), P(A_2|B) , ... , P(A_n|B) 를 계산하여 가장 높은 확률값을 갖는 클래스를 찾으면 된다.
Maximum Likelihood Estimation(최대 우도법)
어떤 모수가 주어졌을 때 원하는 값들이 나올 likelihood를 최대로 만드는 모수를 찾는 방법.
즉 P(B|A_1),P(B|A_2), ... , P(B|A_n) 들의 확률들을 비교하는 것
HMM의 문제점
- Evaluation Problem → forward algorithm (DP)
- Decoding Problem → HMM 핵심 (viterbi)
- Learning Problem → MLE(maximum likelihood method)
기호
Q = 모든 state의 집합
A = Transition probability matrix(state 사이의 transition 확률)
O = Observation sequence
B = Observation likelihood matrix (state에서 Observation이 발생할 확률)
π = Initial probability distribution (state 초기확률)
λ = (A,B) = HMM → HMM이 학습할 대상이자 HMM 자체를 표현하는 기호

Evaluation Problem
가능한 모든 경우의 확률 합
λ를 사용하여 Observation sequence의 등장확률을 구함.
즉 P(O|λ)를 구하는 것
ex) O = (썬글라스, 반팔, 우산, 자켓) =? → 그냥 구하면 너무 많음
Foward Algorithm(Dynamic Programming)을 사용하여 구한다.
Decoding Problem
가능한 모든 경우의 확률의 최대
λ와 Observation sequence에 따른 가장 높은 가능성의 hidden state sequence Q를 찾는 과정
ex) O = (썬글라스, 반팔, 우산, 자켓) 일 때 Q(해, 해, 비, 비)를 찾아내는 것
Viterbi Algorithm을 사용(Forward Algorithm과 유사함)
시간 t일 때 state qi 확률을 가장 높게 만들어주는 경로를 찾고 기억하는 과정을 반복적으로 수행
DP : https://haesunnysideof.tistory.com/6
Learning Problem
HMM λ를 학습
목표 : λ를 최적화 하는 것. 즉 λ = (A, B) 이기 때문에 A, B를 최적화하는것
관측벡터 O의 확률을 최대로하는 λ parameter 찾는것
여러개의 관측 swquence가 있을 때 최적의 HMM parameter 찾기→ MLE
데이터를 기반으로 확률변수의 파라미터를 구하는 방법
어떤 모수가 주어졌을 때 원하는 값들이 나올 우도를 최대로 만드는 파라미터 선택
algorithm
- HMM 초기화
- 적절한 방법으로 P(HMM(λnew))>P(O|HMM(λ))를 찾아라
- 만족스러우면 λ` = HMM(λnew)으로 설정하고 멈춤. 아니면 2번 반복
Cross entropy
두 확률분포의 차이를 구하기 위해서 사용. 실제 데이터의 확률분포와 우리가 계산한 확률분포의 차이를 구하는데 사용한다.
p : 실제 분포, q : 모델링하여 예측하고자 하는 분포
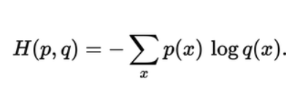
- 예측값과 실제값이 완전히 다른 경우, Cross Entropy의 값은 무한대
- 예측값과 실제값이 완전히 일치하면, Cross Entropy는 Entropy와 동일해짐
- 머신러닝에서 학습이 잘 진행되면, Cross Entropy는 Entropy와 근접해지는 값을 갖게됨
cross entropy와 entropy의 차이가 학습의 정도를 나타내게 되므로 손실함수로 사용한다.
참고 https://theeluwin.postype.com/post/6080524
최대 엔트로피 모델
f : 단어 w에 해당하는 feature들의 모음
feature vector f를 매우 유연하게 설정할 수 있다. 그러나 시퀀스가 아닌 단일 관측치에 대해서만 예측이 가능하다.
MEMM(최대 엔트로피 마코프 모델)
최대 엔트로피모델에서 시퀀스 분류를 가능하게 하는 모델. 은닉상태는 마코프체인을 따른다고 가정하되, 시퀀스에 다양한 자질을 활용하는 방식.
EM(Expectation Maximization) 알고리즘
관측되지 않는 잠재변수에 의존하는 확률 모델에서 최대우도나 최대 사후확률을 갖는 매개변수를 찾는 반복적인 알고리즘이다.
EM 알고리즘은 통계 모델의 수식을 정확히 풀 수 없을 때 최대우도를 구하는데 사용된다. 이 통계모델은 잠재변수와 관측할 수 없는 매개변수, 관측된 데이터로 구성되어있다.
최대우도추정 방법을 사용해서 관측된 데이터에 알맞은 모델의 변수를 추정한다. 초기에 랜덤하게 모델 변수를 설정한 상태에서 관측데이터가 이 모델로부터 생성되었을 확률을 계산한다.
- 매개변수 집합 θ를 초기화한다
- repeat{
- E 단계(기댓값 단계) : θ를 이용하여 샘플별로 K개의 가우시안에 속할 확률을 추정
- M 단계(최대화 단계) : E 단계에서 구한 소속 확률을 이용하여 θ를 추정한다.
- }untile(멈춤조건)
Labeling Bias'자연어처리NLP' 카테고리의 다른 글
NER(Named Entity Recognition) 개체명 인식 (0) 2021.04.13 [NLP]언어 모델 LM(Language Model) (0) 2021.04.09 [NLP]Seq2Seq(sequence to sequence)시퀀스 투 시퀀스 (0) 2021.04.09 [NLP]트랜스포머(Transfomer):Attention Is All You Need (0) 2021.04.09